What’s in a delivery date? Turns out a lot in today’s complex supply chains making lead time calculation very difficult! As discussed in our previous blog article Intersection of Price Product and Availability, customers want to know what product they’re getting, how much it costs, and when they can get it. Each of these questions are answered in increasingly complex ways as manufacturers, distributors, and retailers optimize their operations, supply chains, and diversify their customer touchpoints.
Specifically here, we’ll touch on delivery date or lead time calculation and available-to-promise (ATP). Delivery date comes into play before the order has been promised when a customer is trying to finalize an order. As supply chains optimize, there aren’t as many finished goods in the system so determining delivery dates is more complex than simply checking inventory. Also, in times of limited supply, goods may be tied up with contractual obligations on service levels and allocations. Throw in build to order or mix options, and the myriad of permutations is even harder to predict. Finally, there are transportation issues that could delay or complicate the answer.
When we previously did this for a computer manufacturer, the permutations were so complex, we simply took a statistical average for lead time and used that, then when they couldn’t deliver on time, they’d notify the customer and take the customer satisfaction hit or make them happy by delivering early. But when you’re a manufacturer selling to assemblers or selling through eTailers like Amazon or Ebay, they take delivery dates more seriously and if you miss your date there could be severe consequences.
Accurate Delivery Dates
So how do you limit your inventory exposure and also get an accurate delivery date back to customers? Here are some of the ways we approach it:
Standard Lead Time – As mentioned above, a standard lead time is the easiest to simply put on a product. This is not always the most accurate or desirable method because it means you may have to keep more inventory than needed to maintain service levels. In this case, we typically estimate the lead time by looking at past deliveries and then tweak that on products that are quicker to deliver or take longer using rules.
Available to Promise – Available to promise is a complex mix that combines current orders with delivery dates, service levels, on hand inventory, and future deliveries. Taking all these factors into consideration is difficult when you have a complex supply chain. There are a couple products we use including BlueYonder’s Order Promiser and SAP IBP (formerly APO) that can accurately model all these moving parts and provide a good date. With these systems, you also have the ability to move orders or delay them given service levels or a customer’s willingness to wait.
Allocated Available to Promise – Building on ATP, in industries like semiconductor, there are also allocations to consider and limited supply. These commitments complicate the delivery date answer because you may have firm orders further out that you’ve reserved inventory for, but need to satisfy an order now. The AATP engines can see that you have replenishment orders pending and allow you to consume current inventory expecting that you will be able to satisfy the future orders with new inventory.
Build to Order – Build to order needs a special mention because it complicates the process even more. With build to order or configure to order we typically model the most constrained parts and don’t worry about the other parts that have more availability. We have used the standard lead time method on the constrained parts in the past, such as processors for computer manufacturers, but have also used an ATP engine with the constrained parts. Both methods work and it depends on the situation as to what we would recommend.
Customer Service and Lead Time
In all cases, customers and customer service people need the ability to query the ATP engine for availability or delivery dates when either taking orders, changing orders, or checking order status. Customer service people also need the ability to make decisions like shifting availability when possible or pushing orders out when a customer allows it. In large enterprises, these decisions must also happen in real time so that customers can make their own decisions. As supply chains get more efficient and customers get more demanding, order promising quickly outgrows a customer service reps ability to simply check inventory and these ATP engines can fill that need.
What Next?
If calculating lead time and delivery dates is a problem for you, we can help. Whether you are using SAP, Oracle, some other ERP, or planning tool, we can extract the data and model your supply chain. For more information or to discuss how we can help, please schedule a call!
Agentic AI turns your finance stack into a set of closed-loop workflows that plan, execute, and verify analysis—then hand decisions to humans with evidence. Instead of “copilots” that draft text, these agents query governed data, reconcile results, forecast with uncertainty bands, propose actions, and write back to your ARR Snowball, cash, and board packs—under tight controls.
What “agentic” means in finance
Agentic AI is software that can plan, act, and self-check toward a goal—not just chat. It orchestrates a closed-loop workflow (plan → retrieve → act → verify → handoff), running queries and models on governed data, reconciling results, and proposing or executing actions under constraints with audit trails and approvals. In short: an analyst that does the work, not just drafts it. Here are the high level steps that an agentic AI workflow would take:
Plans the task (e.g., “explain NRR variance vs. plan”),
Retrieves the right definitions and historical context,
Acts by running SQL/Python on governed data and using approved tools (forecast libs, optimizers),
Outputs analysis + recommendations to the target system (Power BI/Tableau, tickets),
Asks approval when money or policy is involved.
Think of an analyst who never forgets the metric glossary, never skips reconciliation, and always attaches their SQL.
Where agentic AI adds real leverage
Here are sample agentic AI workflows—grounded in the ARR Snowball and Finance Hub patterns from this blog series—that deliver real leverage. Each use case plans the task, pulls governed data, runs forecasts/causal/optimization models, self-checks results, and writes back actionable recommendations with owners, confidence, and audit trails. Treat these as templates to pilot on top of your existing Fabric/Snowflake/Power BI stack.
1) Close Acceleration & GL Integrity
This use case runs on top of a governed Finance Hub—the daily, finance-grade pipelines outlined in our Resilient Data Pipelines for Finance. With GL, subledgers (AR/AP), billing, bank feeds, payroll, and fixed assets unified with lineage and controls, an agent can pre-close reconcile, flag mispostings and duplicate entries, propose reclasses with evidence, and attach audit-ready notes—shrinking time-to-close while raising confidence in reported numbers.
Agent:Reconciliation & Anomaly Agent
Does: auto-matches subledgers to GL, flags mispostings, proposes reclasses with evidence and confidence.
Built on the Snowball data model and definitions from ARR Snowball: Proving Revenue Durability, this workflow ingests pipeline, renewals, usage, and billing signals to produce a calibrated forward ARR curve (base/upside/downside bands). It then runs constrained optimization to select the highest-ROI save/expand plays (owners, costs, expected lift) that maximize NRR under budget and capacity, with guardrails and audit-ready lineage.
Agent:ARR Planner
Does: converts pipeline/renewals/usage into a probabilistic forward ARR curve; recommends the portfolio of save/expand actions that maximizes NRR under budget/capacity.
Output: Base/Upside/Downside bands, top drivers of variance, and a monthly action schedule (owners, due dates).
3) Cash Flow with Contract Awareness
Building on the Cash-Flow Snowball outlined in Extending Snowball to Cash & Inventory, this agent (“Cash Orchestrator”) turns contracts into cash signals: it extracts renewal and payment terms, unifies AR/AP with governed ledger data, and constructs a calendarized view of expected inflows/outflows. From there, it runs a 13-week stochastic cash simulation and proposes term mixes (early-pay incentives, cadence, invoicing options) that improve cash conversion cycle (CCC) without eroding NRR—backed by bi-objective optimization (NPV vs. CCC) and full audit trails.
Agent:Cash Orchestrator
Does: extracts terms from contracts, joins AR/AP, simulates collections & payment runs, and proposes term mixes (early-pay incentives, cadence) that improve CCC without hurting NRR.
Extending the approach in Cost Allocation When You Don’t Have Invoice-Level Detail, this workflow ingests GL lines, vendor metadata, PO text, and operational drivers (products, jobs, regions). An agent uses embeddings and probabilistic matching—constrained to reconcile totals back to the GL—to propose allocations with confidence scores, surface exceptions for human approval, and write back auditable adjustments. The result is consistent product/segment margins and board-ready views even when source detail is sparse.
Agent:Allocator
Does: maps GL lines to drivers (products, jobs, regions) using embeddings + historical patterns; produces confidence-scored allocations with human approval.
Tech: weak supervision, constrained optimization to keep totals consistent with the GL.
5) Variance Analysis that’s Actually Causal
Built on the Snowball definitions from ARR Snowball: Proving Revenue Durability, this agent explains “why” by linking changes in NRR/GRR to causal drivers (onboarding TTV, pricing, usage) with sourced metrics and lineage.
Agent:Root-Cause Analyst
Does: traces “why” using causal graphs: e.g., NRR −2 pts ← onboarding TTV +9 days in SMB-Q2 cohort ← implementation staffing shortfall.
Tech: causal discovery + do-calculus; renders a sourced narrative with links to metrics and lineage.
Reference architecture
This high level reference architecture is used to run agentic AI on your existing lakehouse/warehouse without changing metric logic. It separates concerns into a governed data plane (tables, lineage), a knowledge plane (versioned metric contracts + vector store), a compute/tools plane (SQL/Python, forecasters, optimizers), orchestration (events, schedules, retries), and governance/observability (policy engine, approvals, audit, PII).
Irrespective of the underlying framework, the architecture can work through connectors for Microsoft Fabric, Snowflake, or Databricks and the workflow pattern stays the same, with outputs back to BI (Power BI/Tableau).
Data plane: governed lakehouse/warehouse; metric contracts (GRR/NRR definitions) in a versioned glossary.
Governance: policy engine (who can do what), audit log of every query/action, PII redaction, secrets vault.
UX: push to BI (ARR Sankey/forecast bands), create tickets, and draft board commentary with citations.
How it runs: the agent loop
Now that we’ve covered the use cases and architecture, this list shows the runtime lifecycle every agent follows—plan → retrieve → act → verify → propose → approve → learn—so outputs are consistent, governed, and easy to audit across ARR, cash, and close workflows.
Plan: build a step list from the request (“Explain NRR miss in Sept”).
Retrieve: pull metric definitions + last 12 months context.
Act: run parameterized SQL/Python; if a forecast, produce bands + calibration stats (MAPE/WAPE).
Verify: unit tests (sums match GL), reasonableness checks (guardrails), anomaly thresholds.
Approve: route to owner; on approve, write back tags/notes and schedule the action.
Learn: compare predicted vs. actual; update models monthly.
Putting it to work: example workflow map
With the loop defined, here’s how it lands in operations: a simple runbook of when each agent fires, the data/tools it uses, the outputs it produces, and the owner/KPIs who keep it honest. Use this as your starting calendar and adjust SLAs and thresholds to your portfolio.
Workflow
Trigger
Tools & data
Primary outputs
Owner
KPIs
NRR Forecast & Action Plan
Monthly Snowball review
Usage, CRM, billing, optimizer
Forecast bands; top 10 save/expand plays
VP CS / RevOps
NRR Δ, WAPE, action adoption
Close Reconciliation
EOM −2 to +3
GL, subledgers, anomaly detector
Reclass proposals, risk heatmap
Controller
Close time, reclass rate, % auto-accepted
Cash Horizon
Weekly
Contracts, AR/AP, scenarios
13-wk cash projection; term mix recs
CFO
CCC, DSO/DPO, forecast error
Cost Allocation Assist
Monthly
GL, drivers, embeddings
Allocation file + confidence
FP&A
% manual effort saved, variance to audited
Variance Root Cause
On miss > threshold
Snowball, staffing, pricing/events
Causal narrative + corrective plays
FP&A / Ops
Time-to-cause, fix adoption
A simple agent spec (YAML)
To make agents portable and auditable, define them in YAML—a compact, declarative contract that captures the agent’s goal, allowed tools/data, ordered steps (the agent loop), validations/approvals, outputs, and schedule. Checked into Git and loaded by your runner, the same spec can move from dev → stage → prod on Fabric/Snowflake/Databricks with no code changes—just configuration—while enforcing policy and producing consistent, testable results.
Because agentic AI touches dollars and board metrics, it has to run inside hard guardrails. This section defines the essentials: human-in-the-loop approvals for any dollar-impacting change, metric contracts (immutable GRR/NRR and inflow/outflow definitions), full lineage & audit logs for every query/model/output, drift & calibration monitors on forecasts and propensities, and strict privacy/PII controls. Treat these as deployment preconditions—what turns smart helpers into accountable systems your CFO and auditors can trust.
Human-in-the-loop on money: any dollar-impacting change requires approval.
Metric immutability: lock GRR/NRR/inflow/outflow in a versioned contract; agents must cite the version they used.
Lineage & auditability: store SQL, parameters, model versions, and checksums with each output.
Drift & calibration: monitor forecast error (WAPE/MAPE), probability calibration, and retrain schedules.
Security & privacy: least-privilege credentials, PII redaction at ingest, fenced prompts (no exfiltration).
Anti-patterns to avoid
These are the failure modes that turn agentic AI from “decision engine” into noise. Dodge them up front and your CFO, auditors, and operators will trust the outputs.
Unfenced LLMs on production data. No metric contracts, no sandbox—answers drift and definitions mutate.
“Assistant-only” deployments. Agents that never write back, never learn, and never close the loop (no actions, no feedback).
Global rates for everyone. One churn/expansion rate across cohorts hides risk; segment or cohort is mandatory.
Unlogged or unapproved actions. No SQL lineage, no approvals for dollar-impacting changes.
Moving the goalposts. Changing GRR/NRR or inflow/outflow definitions midstream without versioned metric contracts.
Double counting. Mixing bookings with ARR before go-live; counting pipeline twice in forecast and Snowball.
Black-box models. No calibration, drift monitoring, or error bounds—pretty charts, unreliable decisions.
Security shortcuts. PII/secrets in prompts, excessive privileges, no redaction or audit trails.
Bypassing orchestration. One-off notebooks/demos with no schedules, retries, or SLAs—results aren’t reproducible.
How to know it’s working
Agentic AI should pay for itself in numbers you can audit. This section defines a small, non-negotiable scorecard—measured against a naïve baseline or A/B holdouts—that agents publish automatically after each run: forecast accuracy and calibration, incremental NRR/cash improvements, action adoption and uplift, and close/reconciliation gains. Targets are set up front (e.g., WAPE ≤ 8%, NRR +Δ pts vs. rank-by-risk, CCC −Δ days), with links to lineage so every win (or miss) traces back to data, SQL, and model versions.
Close: −X days to close; >Y% anomalies caught pre-close.
Forecast: portfolio WAPE ≤ 6–8%; calibration within ±2 pts.
ARR: NRR +Δ pts vs. rank-by-risk baseline; save/expand uplift with A/B evidence.
Cash: CCC −Δ days; hit rate of collections predictions.
Productivity: % narratives auto-generated with citations and human-approved.
Conclusion
Agentic AI isn’t about prettier dashboards—it’s about decision engines that plan, act, and verify on your governed data. Tied into ARR Snowball, cash, and cost flows—with definitions, controls, and owners—these workflows compound accuracy and speed, month after month, and turn financial analysis into a repeatable operating advantage.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
Snowball is a general-purpose flow lens, not just a SaaS metric. The same Sankey-style visualization that clarifies ARR—inflows, outflows, and the net build with velocity/acceleration—translates cleanly to other operating flows. For cash, it traces invoices and receivables through collections alongside payables and disbursements to reveal net cash build, DSO/DPO, slippage, and CCC. For inventory, it maps receipts to on-hand (by age), then to WIP, shipments/returns, and scrap, exposing turns, DIO, and leakage. Use the same monthly cadence—scorecard, flow diagnostics, actions with owners—to turn hidden movement into decisions that protect runway and margin.
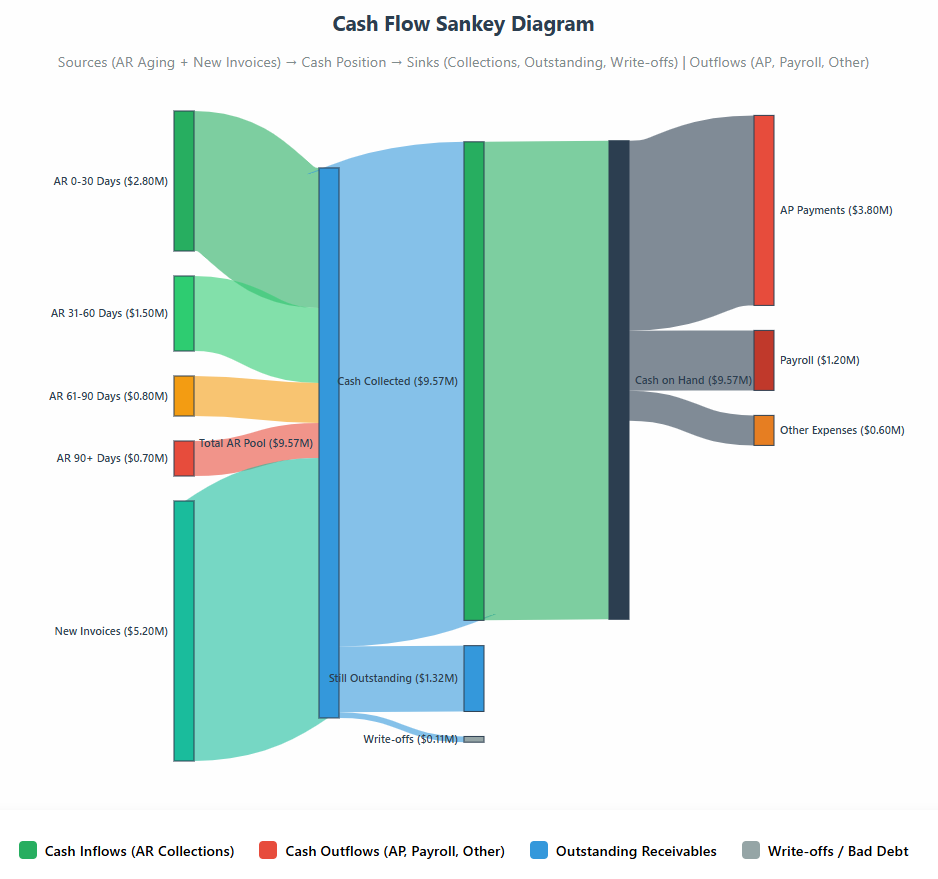
Cash-Flow Snowball (AR ⇄ AP ⇄ Cash)
Turning attention to cash flow, the same Snowball lens maps how dollars enter as invoices (AR), age through buckets, and convert to cash—while in parallel showing how purchases become AP and flow out as disbursements. A Sankey-style view makes sources and sinks obvious at a glance (collections, slippage, write-offs; payroll, vendors, taxes), and a monthly scorecard tracks net cash build, its velocity, and acceleration. The result is an operating picture you can act on: tighten or relax payment terms, target early-pay discounts, adjust payment run cadence, prioritize supplier payments, and focus collections where aging migration signals risk. Pair the flow with DSO/DPO/CCC and a simple Collections Efficiency = Cash Collected ÷ (Opening AR + Invoiced) to turn cash visibility into runway and working-capital gains.
What it is. A flow view of dollars from invoices → receivables → cash collected, and from purchases → payables → cash paid, producing a net cash build curve (and its velocity/acceleration) each month. Use a Sankey to show sources (AR aging buckets, new invoices) and sinks (collections, bad debt) alongside outflows (AP aging, payroll, taxes, capex).
Key inputs. AR ledger (invoice dates, due dates, terms, aging), AP ledger (bills, terms), cashbook, payment runs, pipeline-to-invoice assumptions, and expected payment schedules.
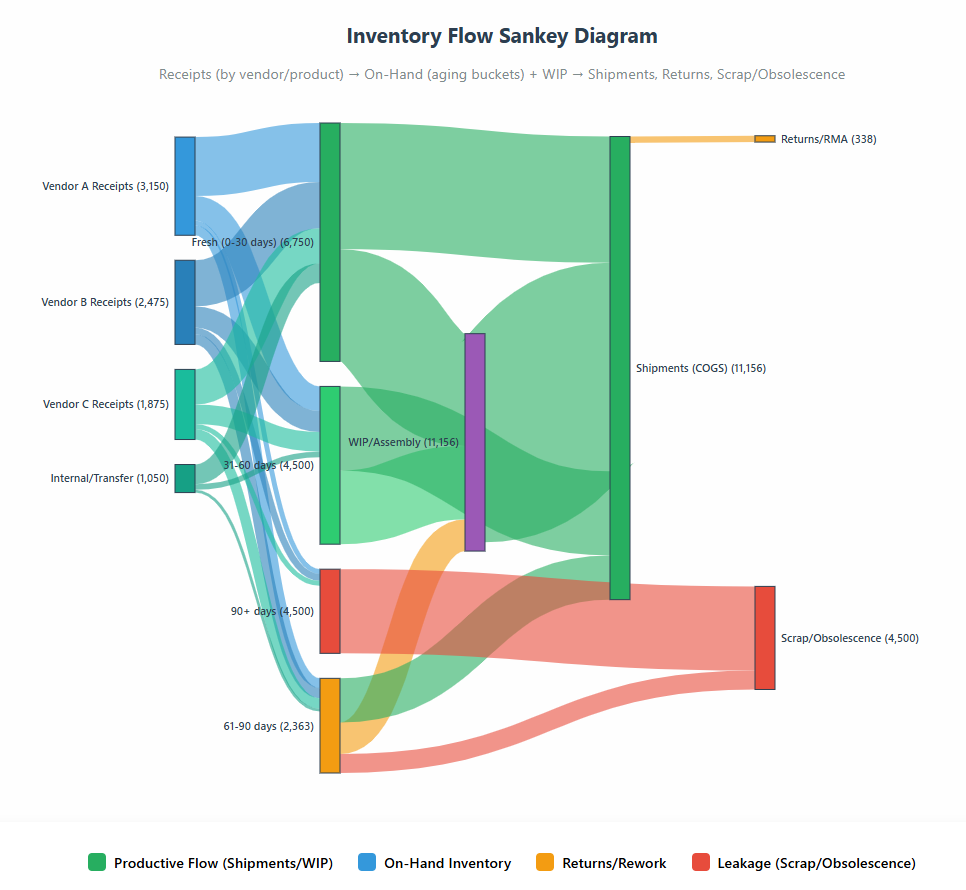
Here’s how the same Snowball lens powers inventory: map receipts into on-hand (by age buckets), through WIP/consumption, and out as shipments/returns/scrap. In a Sankey-style view, link thickness shows volume while color separates productive flow from leakage (shrink, obsolescence). Run it by cohort (receipt vintage), product family, vendor, or location to spot slow movers early, tune ROQ/ROP and safety stock, and align purchasing with real demand. A simple scorecard—net inventory build, throughput velocity, turns/DIO, and leakage—turns visibility into actions like throttling receipts, markdowns, vendor returns, or WIP gating to protect margin and service.
What it is. A flow of units (and dollars) from receipts → on-hand (age buckets) to WIP/consumption → shipments/returns → scrap/obsolescence. Track net inventory build, throughput velocity, and leakage (shrink/obsolete) by cohort (receipt vintage), product family/SKU class, vendor, or location.
Throttle receipts or replan ROQ/ROP where excess days supply is high; expedite only for cohorts with proven demand velocity.
Markdown/liquidate aging cohorts before they cross obsolescence thresholds; vendor returns where contracts allow.
Postponement/late-stage assembly to reduce variant risk; vendor rationalization when shrink/defect rates spike.
Safety-stock tuning by forecast error and service target; WIP gating if flow is blocked downstream.
Conclusion: one lens for flows that drive value
Extending the Snowball lens to cash and inventory gives you a single way to see—and manage—your most important flows: dollars, units, and revenue. The result is earlier signals and fewer surprises: net cash build with DSO/DPO/CCC guardrails, inventory throughput with turns/DIO and leakage, and the same Sankey-style visibility you use for ARR. Run one monthly cadence—scorecard → flow diagnostics → 2–3 actions with owners—and you’ll turn visibility into working-capital gains, margin protection, and a stronger balance sheet. Lock a simple taxonomy, keep definitions stable, and track movement over time. One lens, three flows: compounding revenue, healthier cash, and smarter inventory—operated to value.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
Finance teams live and die by the quality of their numbers. Executives expect reports that are repeatable, auditable, and on time—while operations demand fresh data and engineering just wants systems that don’t break every close. The reality is that finance data isn’t static: source systems update late, postings get rebooked, and every entity has its own timing quirks.
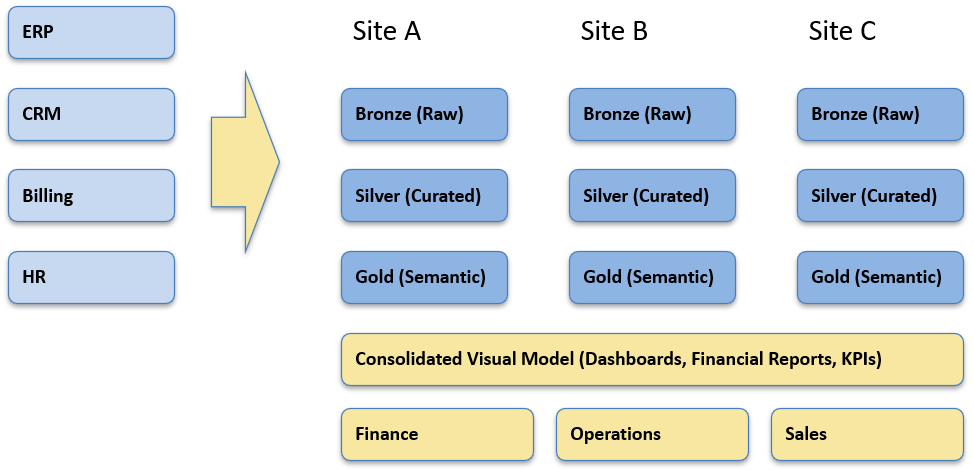
The way through is disciplined data architecture. A resilient pipeline is idempotent (runs twice, lands once), replayable (can reprocess history cleanly), and observable (tells you what ran and what failed). Organize it around a simple, layered pattern—Bronze (raw), Silver (curated), Gold (semantic/reporting)—and enforce clear controls for backfills and late-arriving data.
Get this right and month-end shifts from a scramble to a routine: reproducible for finance, fresh for operators, and calm for engineering.
What We Mean by “Finance Data”
When we talk about finance data, we’re not referring to a single ledger table or dashboard. It’s an ecosystem of structured, governed information that must balance precision with traceability—from monthly summaries all the way down to individual invoices. Finance depends on both the summarized view that closes the books and the granular transactions that explain where every number came from.
Summary-Level Reporting: The Ledger View
At the top of the stack is the governed layer used for financial reporting—your trial balance, chart of accounts, locations, and fiscal calendar. This is where finance teams confirm that debits equal credits, that every account rolls up correctly to a report line, and that each entity is aligned to the proper fiscal period.
The trial balance aggregates balances by account, entity, and period; the chart of accounts defines the financial language—assets, liabilities, revenue, and expense—that underpins every report. Locations and entities anchor results by site or legal company, and the fiscal calendar dictates how those periods close and roll forward.
Layered on top are standardized sales categories, departments and report lines that map GL accounts into a repeatable P&L structure. These definitions form the backbone of every recurring financial report—the numbers that executives, auditors, and investors expect to match period over period.
Transactional Drill-Downs: The Detail Behind the Numbers
Beneath the summary lies the transactional world that generates those balances. This is where reconciliation, audit trails, and operational insight live. Finance teams need to be able to drill from the GL summary into the individual invoices, journal lines, customers, vendors, and salespeople that created each amount.
On the revenue side, that means access to invoice and order data—customers, items, quantities, prices, discounts, taxes, posting dates, and sales reps—so analysts can trace a line of revenue back to its source. On the expense side, it includes vendor bills, payments, and purchase orders, providing visibility into timing and accruals. Supporting all of this are the customers, vendors, items, and employees that act as shared reference dimensions—the master data that links every transaction to the correct reporting bucket.
Accounts Receivable (AR) and Accounts Payable (AP) use this same data fabric. AR needs consistent customer hierarchies and invoice statuses for aging and collections; AP relies on vendor details, due dates, and payment records for cash planning. Together, these systems form the operational substrate beneath the general ledger—where transactional truth supports financial accuracy.
What “resilience” means for finance data
Once you understand what finance data really encompasses—from the governed trial balance to the line-level invoices that feed it—the next challenge is keeping that ecosystem stable. Finance can’t afford surprises: the same source data should always yield the same result, no matter when or how many times the process runs.
That’s where resilience comes in. In a world of daily extracts, late files, and ever-changing operational systems, a resilient pipeline ensures that finance gets repeatable numbers, operations get freshness, and engineering gets sleep. It’s the difference between firefighting every close and simply rerunning a trusted process.
Resilience centers on three concepts:
Idempotent. Every step can run twice and land the same result. Use deterministic keys, truncate-and-load or MERGE with natural/surrogate keys, and avoid “append without dedupe.”
Replayable. Reprocess any window (e.g., “last 45 days”) without one-off scripts. Keep a watermark per source and parameterize transforms by date range.
Observable. Always answer “what ran, what failed, what changed.” Maintain a run_log (run_id, start/end, rows in/out, status), dq_results (tests, thresholds, pass/fail), and lineage (source files, batch IDs) that finance can see.
For finance, repeatability from the same source is non-negotiable.
Reference architecture blueprint
If resilience is the behavior we want, this is the shape that produces it. The architecture’s job is simple: preserve traceability from raw files to governed outputs, keep history reproducible, and give Finance a single, contracted place to read from. Each layer has a narrow purpose; together they create stable, auditable flow.
Bronze (raw). Land data exactly as received. Keep file/batch metadata, load timestamps, and source checksums. Store both snapshots (periodic full extracts for sensitive tables like COA) and CDC/deltas (invoices, payments, usage).
Silver (curated). Normalize types, fix obvious data quality, generate stable surrogate keys, and standardize enums (status codes, currencies). Apply report-line mapping for GL and basic conformance across entities.
Gold (semantic). Star schemas and a governed semantic model—fact_gl, fact_invoice, dim_customer, dim_item, dim_date, etc.—with measures defined once for BI.
History Without Headaches: SCDs That Reproduce Month-End
You’ve defined the finance data surface (summary + drill-downs) and shaped the pipeline (Bronze/Silver/Gold). The last ingredient is history semantics: how labels, hierarchies, and attributes evolve without breaking prior periods. Month-end trust depends on rerunning any past close and getting the same roll-ups and joins. That’s what slowly changing dimensions (SCDs) provide when they’re applied deliberately—not everywhere, only where the business meaning changes.
GL Accounts / Report Lines. Usually SCD-1 on names/descriptions (keep current labels), but maintain effective-dated mapping rules so past months reproduce the exact roll-up.
Customers / Items. Use SCD-2 for attributes that affect analysis (industry, segment, item family). Surrogate keys enable stable joins; valid_from/valid_to makes time-travel simple.
Reference bridges. For many-to-many (e.g., customer ↔ parent org), use bridge tables with effective dating to keep joins cheap and auditable.
Handling Backfills and Late-Arriving Facts During Close
Even with well-designed SCDs and stable keys, the month-end close is where resilient pipelines prove their worth. This is when new files arrive after cutoff, rebooks shift timing, or manual corrections appear just as finance wants to lock results. Without guardrails, these timing mismatches cause re-runs, mismatched balances, and sleepless nights.
The solution is to design for imperfection—to expect late data, rolling windows, and controlled reprocessing rather than firefighting. A resilient pipeline doesn’t panic when something posts late; it simply replays the window and reconciles automatically.
Rolling reprocess window. Always recompute the last N days (e.g., 45–60) so rebooks, timing fixes, or late files correct automatically.
Dual-calendar discipline. Track document date, service period, and posting date. Choose one to drive reporting; persist the others for reconciliation.
Freeze with exceptions. Let finance “freeze” a period in Gold once signed off; still allow Bronze/Silver updates. Approved adjustments flow via a controlled adjustments table, not ad-hoc edits.
Deterministic tie-backs. Recompute invoice line totals in Silver and compare to GL in Gold. Variances above a threshold open an investigation item rather than silently passing.
Observability: tests, freshness SLAs, run logs
You’ve designed for history (SCDs) and timing (rolling reprocess with freeze-and-exceptions). The last piece is visibility: when late files or rebooks happen, everyone should immediately see what ran, what’s late, and what changed. Treat data quality like automated QA and expose the operational truth in the same place people read the numbers.
Start with a compact test suite at Silver/Gold—schema/required fields, reconciliations (TB, AR aging, cash), uniqueness on (site, doc_id, line_no), and simple MoM/YoY variance bands. Write every result to a dq_results table with thresholds, owners, and pass/fail, and pair it with a run_log that captures run_id, job, layer, start/end, status, rows in/out, and upstream batch/file identifiers. Then surface both in your BI model so anyone can answer, at a glance, “what’s green, what’s red, and why.”
Publish dataset-level freshness SLAs (e.g., invoices by 06:00; GL by T+1) and show a visible “Data as of …” banner when an SLA is missed. If a site is delayed, don’t block portfolio views—load them, exclude the late site, and label the omission clearly. With these thin contracts (dq_results, run_log, and freshness SLAs) your pipeline behaves like a product: repeatable numbers, transparent delays, targeted fixes—not guessing.
From Pipeline to Trust: Semantic Layer Contracts
After you’ve built resilient Bronze/Silver/Gold flows, the “last mile” is where trust is either confirmed or lost. Treat the Gold layer as a contract, not just a set of tables. That contract defines the public surface area—table names, column names and types, the grain of each table, and the official definitions of measures like Revenue, COGS, and Gross Margin—so they match the finance manual exactly. When the contract is explicit, reports become predictable and auditors stop negotiating definitions.
Stability is the rule. Don’t change columns in place; add new ones, deprecate with a timeline, and maintain a compatibility view so existing dashboards keep working while teams migrate. Keys should be stable (surrogate where needed), names should be durable, and any changes should ship with a clear changelog in the model repo.
Keep the math in one place. Centralize calculations in the semantic layer (DAX or your chosen semantic engine) so every report uses the same measures. If a metric changes, you update it once and every dashboard inherits the fix—no more drift between teams.
Putting It Into Practice
Resilience isn’t a grand theory—it’s a few disciplined habits applied every day. Land Bronze exactly as received (snapshots for small, point-in-time tables; CDC for high-volume facts). Shape Silver for clean types and keys, SCDs where history matters, and effective-dated report-line mappings. Publish Gold as a contract—stable schemas and single-definition measures that mirror the finance manual.
Operationally, reprocess a rolling window so late files and rebooks resolve themselves; freeze closed periods in Gold and route changes through a controlled adjustments lane. Instrument the whole path with run logs, DQ results, and freshness SLAs surfaced in BI so everyone can see what’s green, what’s red, and why.
Do those things consistently and month-end becomes routine: reproducible for finance, fresh for operators, and calm for engineering.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
Recurring models, such as SaaS companies, live and die on retention and expansion, not one-time bookings. ARR Snowball decomposes revenue into inflows (new, expansion) and outflows (contraction, churn), yielding clean GRR/NRR and velocity/acceleration trends that expose true revenue durability. Because it’s cohort-aware and definition-consistent, it avoids P&L masking, ties directly to operating levers (pricing, onboarding, CS), and makes forecasts and valuation more defensible—hence its status as the go-to measure of financial soundness in SaaS.
Traditional P&L is great at telling you what happened. ARR Snowball shows how revenue flows—what’s coming in (new logos, expansion) and what’s leaking out (contraction, churn)—so you can see the net build, velocity, and acceleration of growth over time. That makes durability visible, which is exactly what investors pay for.
Why Snowball beats a P&L
A P&L aggregates; Snowball decomposes. By separating inflows and outflows, you expose the levers that actually move valuation:
Retention and expansion, not just totals. Snowball isolates GRR/NRR, showing whether growth is compounding from the base or masked by constant new-logo replacement.
Early risk detection. Month-over-month velocity and acceleration reveal when growth is slowing even if the top line still looks fine. Cohorts (by vintage, product, or segment) make where it’s slowing obvious.
Operational linkage. Because the flows are explicit, you can tie movements to pricing, onboarding, success plays, and renewal hygiene—and measure the effect the very next month.
Efficiency & LTV. Combine flow with cost-to-serve to monitor LTV, payback, and a simple durability gauge: Efficiency = inflow ÷ (inflow + outflow). A rising efficiency trend almost always precedes multiple expansion.
Revenue Flow
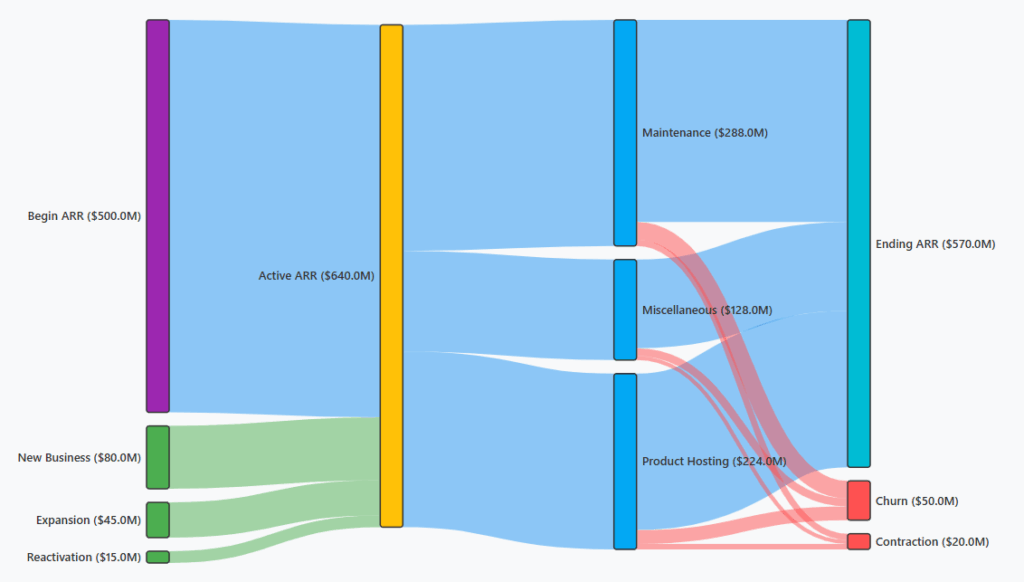
Traditional ARR Snowball analysis focuses on a waterfall chart which shows the net change. A better way to visualize the revenue flow is in a Sankey diagram as outlined below.
A Sankey shows where it came from and where it went—which is what operating and diligence teams need. Using a data cube behind the chart allows deeper analysis by isolating cohorts and breaking down flow through different metrics.
Provenance → routing → outcome. Starting ARR splits into new, expansion, contraction, and churn streams; link thickness encodes magnitude so leakage is unmistakable.
One view, many dimensions. You can branch by cohort, product, or segment without creating six separate charts. Colors communicate direction (inflow vs. outflow) instantly.
Faster pattern finding. Thick outflows from a specific cohort or product highlight where to intervene; thick expansion streams identify “expansion heroes” worth doubling down on.
Still keep a mini waterfall. A slim row of monthly bars is perfect for net build and velocity; the Sankey carries the richer “how and where” story.
Using this chart as a starting point, an analyst can quickly visualize and drill into problem spots such as churn. Expanding the chart over multiple time periods can show trends and patterns more effectively. The chart also serves as a launchpad for forecasting and planning.
Operating to value
ARR Snowball turns “are we growing?” into “what’s compounding, what’s leaking, and what do we do next?” By visualizing inflows vs. outflows and the net build each month, you get an early-warning system (velocity/acceleration), a shared language with Finance (GRR/NRR), and a single place to assign owners and budget to the highest-yield levers. The outcome is fewer surprises, faster course-corrections, and a consistent story you can defend to the board—and eventually to buyers.
Incorporating the Snowball into monthly planning helps keep management focused on the overall goals instead of their own silos. Here is a monthly agenda that is supported by the accompanying metrics playbook:
Scorecard: net ARR build, velocity/acceleration, variance to plan.
Flow diagnostics: top inflow/outflow drivers, cohort hotspots.
Actions: 2–3 interventions with owners/dates; confirm expected impact.
Capital allocation: shift dollars/CS capacity where compounding is strongest.
Sample Operating Metrics and Actions
Every organization is different and would have a different mix of metrics to use for monitoring ARR. Here are some common metrics and the resulting actions when the metric is off track:
Metric (formula)
What it signals
Operator decisions & plays
Net ARR Build(Ending ARR − Prior Ending ARR)
Overall compounding pace vs. plan
If down: isolate inflow vs. outflow drivers; assign owners; set 30-day fixes.
Velocity(Δ Net Build MoM) & Acceleration(Δ Velocity MoM)
Allocate senior reps to high-ARR/at-risk logos; pre-approve save offers; escalate blockers early.
Pricing & Discount Leakage (seen as contraction)
Margin & positioning problems
Tighten discount bands; adjust price fences; rebundle to defend ACV.
Concentration Risk (Top-10 % of ARR)
Resilience & diligence risk
If rising → diversify pipeline; accelerate expansion in under-penetrated segments; scenario-test downside.
LTV & Payback (with cost-to-serve)
Where to invest next
Fund segments with superior LTV:CAC and fast payback; sunset low-yield motions; revisit support model.
Incorporating forecast into the flow
The previous breakdown focused on a historical view, but the same process can be used for future planning and forecasting. The ARR Snowball visualizes your pipeline, renewals, and expansion opportunities into an ARR-based sales forecast: each deal is mapped to a go-live month and ramp, renewals carry probability and expected expansion/contraction, and the result is a forward ARR curve that Sales uses to set targets and coverage, plan capacity/territories, and make in-quarter course corrections. It keeps bookings honest (no double counting before go-live) and turns the forecast into an operating tool—updated monthly as usage and deal health change. Again, different companies would have different metrics to track, but here are a few that could be used:
Renewal ladder: 30/60/90/180-day schedule with logo/ARR, term, and owner.
Health & probability: assign a renewal probability by segment/cohort using leading indicators (usage, activation, support load, executive sponsor, discount level).
Expansion/contraction baselines: segment-level rates (e.g., +x% upsell, −y% contraction) back-tested on the last 12–24 months.
New business feed: stage-weighted pipeline → ARR start date and ramp curve (e.g., 50% of ACV recognized in month 1, then full run-rate).
Pricing & terms: planned changes (uplifts, bundles, annual vs. monthly) applied to the right cohorts to prevent double counting.
Conclusion: durable, repeatable growth you can prove
ARR Snowball turns the data you already have into a living operating view—showing where revenue is compounding, where it’s leaking, and what to do next. By separating inflows and outflows and tracking velocity, acceleration, GRR/NRR, and cohort health, you move from retrospective reporting to a monthly cadence of targeted action that compounds value over the hold period.
What you gain, consistently:
Clarity on revenue quality. A clean record of GRR/NRR, inflow/outflow mix, and cohort durability—so you’re managing compounding ARR, not masking churn.
A forecast you can run. Renewal ladders, probability-weighted expansions/contractions, and simple scenarios produce a forward ARR curve Sales and Finance both trust.
Attribution and repeatability. Before/after evidence ties pricing, onboarding, and CS plays to retention and expansion, making wins repeatable.
Risk transparency. Concentration, contraction pockets, and churn lineage are quantified—with mitigations owned and in motion.
Valuation logic. Stronger NRR bands, stable cohorts, and steady net build create a defensible bridge from operating metrics to premium multiples.
Bottom line: Snowball gives you truth about the past and signal for the future—then turns that signal into accountable next steps. Use it as your monthly heartbeat to operate to value and keep the revenue story you’ll tell at exit writing itself.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
When a company lacks job-level costing, margin analysis stalls. At one client, direct materials, outside services, and labor weren’t tied to jobs; freight revenue was visible, but final freight costs were negotiated monthly with brokers, so the actuals arrived late. We implemented a cost allocation model that provided a transparent, finance-grade allocation for estimating costs at the invoice line level, reconciled to the GL, and scaled across locations.
Why this problem is hard
Solving this problem was not simple. The team was under stressful time pressure because of an event and while the approach was solid, there were nuances that required tweaks due to the realities of the data. The issues below were some complicating factors:
No job detail: Materials and services hit the GL in aggregate as the movement per month.
Mixed taxonomies: Sales categories (how revenue is grouped) didn’t align neatly with cost categories (how expenses post).
Late freight actuals: Costs are re-priced at month-end based on volume discounts, so early views are incomplete.
Journal entries on GL: Invoice totals didn’t always match GL revenue because of journal entries and other accounting quirks.
Location nuances: Each location had individual nuances in their accounting such as how sales, costs or freight was tracked.
Intercompany transfers: Intercompany transfers were handled differently and needed to be removed for calculations.
The goal wasn’t perfection—it was decision-grade estimates that reconcile to the books and hold up in reviews. The algorithm did not account for customer specifics or labor cost which is another important component for margin calculations.
Inputs and setup
The algorithm ran monthly after month-end-close when the books were finalized. Prior to month end, many invoices were still pending, general ledger needed tweaks, and freight cost wasn’t finalized and the algorithm was dependent on each of these sets of monthly data:
Revenue by sales category from the GL.
Cost by cost category from the GL.
Invoice revenue by sales category from invoices.
Freight cost and revenue from the GL.
Freight cost and revenue from invoices (some locations tracked cost and others revenue per invoice).
Weight matrix (management-estimated, per location, per month) indicating how much each cost category contributes to each sales category (weights per cost category sum to 1.0).
Governance: weights are effective-dated, approved by location leadership, and versioned.
Step by step explanation of cost calculation
We start from what’s authoritative—the general ledger. Each month (and for each location), we take the GL cost pools (e.g., Direct Materials, Outside Services) and apportion them to sales categories (e.g., Product, Services, Project, Freight) using a simple, auditable rule: management supplies weights that describe how much each cost category supports each sales category. To make those weights reflect the books, we align invoice revenue to GL revenue once per category. Then we push the allocated dollars down to individual invoices in proportion to line revenue (excluding intercompany), so every invoice line carries a defensible share of costs. Finally, we reconcile back to the GL so totals match and any variance is explained.
Summary of the allocation flow
Build the invoice view. For each month and location, sum invoice revenue by sales category, explicitly excluding intercompany lines. This gives the proportional “shape” we’ll use later.
Anchor to the ledger. Sum GL revenue by those same sales categories and compute a category-specific scaling factor (GL ÷ invoice). This aligns invoice activity to booked revenue without double-counting.
Identify the cost pools. Sum GL cost by cost category (e.g., Direct Materials, Outside Services, Freight Cost). These are the dollar totals you must preserve.
Apply management weights. Use the approved weight matrix (cost category × sales category) to blend business judgment with GL-aligned revenue, producing a fair share of each cost pool for each sales category.
Turn shares into dollars. Multiply each share by its GL cost pool to get allocated dollars per sales category. Because you allocate from GL costs, category totals remain exact for the month.
Push to invoice lines. Within each sales category, distribute its allocated dollars to invoice lines in proportion to line revenue (again, excluding intercompany from the denominator). Now every line carries cost by category, enabling customer, product, and location margin views.
Reconcile and log. Verify that the sum of all line allocations equals the GL cost pools (within rounding). Record pass/fail, any variance reason (e.g., timing, credits, exclusions), and approver, so the process is repeatable and audit-ready.
Intercompany handling: Intercompany transfers are removed from the invoice revenue used for weighting and handled under a separate policy (e.g., zero cost on those lines or an “Intercompany” bucket that’s excluded from profitability views).
Detailed calculation sequence
This method allocates monthly GL costs to invoice lines using a management weight matrix, while preserving GL totals. Intercompany (IC) transfers are excluded from invoice revenue used for weighting and handled separately at the end.
Aggregate invoice revenue by sales category (exclude intercompany)
For each location ℓ and month m, sum invoice line revenue for each sales category s, excluding intercompany lines. This builds the invoice-side view used for proportional allocation within the month.
Compute the GL↔Invoice scaling factor per sales category
Align invoice revenue to GL revenue once per category with a scaling factor. Handle zero or negative invoice totals with a documented fallback (e.g., default to 1.0, carry forward, or skip allocation for that category).
Sum monthly GL costs for each cost category c (e.g., Direct Materials, Outside Services, Freight Cost, Labor/Overhead if in scope). These are the dollar pools you will allocate.
Define and approve the cost allocation weight matrix
Management provides weights w that express how much a cost category contributes to each sales category (by location and month). For each cost category, weights must be non-negative and sum to 1.0. Version, date, and approve these values.
\[\displaystyle \sum_{s} w_{c,s,\ell,m} \;=\; 1 \quad \text{for each } c\]
Compute weighted revenue by (cost category, sales category)
Blend business judgment (weights) with scaled invoice revenue. Using k ensures shares reflect GL-level revenue without double-scaling later.
Within each sales category s, allocate its share of each cost category to invoice lines in proportion to line revenue (still excluding intercompany lines from the denominator). Sum across cost categories to get total line cost.
Intercompany handling: IC lines are excluded from allocation. You may set their line cost to 0, or place into a separate “Intercompany” bucket that is omitted from customer/product profitability views.
Reconcile to GL and record variances
Verify that line-level allocations sum to GL totals for each cost category and month (within rounding). Capture pass/fail status, variance (if any), and reason codes (e.g., timing, credits, exclusions). This makes the method audit-ready.
Zero/negative revenue: If \[\displaystyle R_{s,\ell,m}=0\], use a policy fallback (e.g., quantity shares, carry-forward weights, or skip that category).
Weights governance: Effective-date and approve weights monthly; keep rationale by location.
Freight & late actuals: If freight costs arrive after month end, use a provisional ratio during the month and true-up when actuals post, allocated proportional to freight revenue.
Freight costs that arrive late
Freight must be handled differently than other costs. In the case of freight, some locations included freight in the invoice, so freight cost per invoice was hidden. In other cases, freight cost was on the invoice, but revenue was not. In the final case, freight revenue was on the invoice but cost was not. A site by site adjustment was created to accommodate the differences.
Provisional allocation: Calculate a trailing-average of GL Freight Cost : GL Freight Revenue ratio per location to provisionally allocate freight cost to freight revenue lines during the month.
Month-end true-up: When actuals post, compute the delta and reallocate across that month’s freight lines proportional to freight revenue.
Location differences: When freight was not on the invoice, use the GL Fright Cost as a ratio to the monthly GL Revenue then apply that to each invoice line item. Alternatively when there was freight revenue or cost on the invoice, apply the appropriate ratio adjustment to each line item.
Audit: Record adjustments with effective dates and rationale.
Handling direct labor and contract labor costs
In this case, labor was not job-coded consistently but manufacturing labor was tracked through COGs. A similar set of calculations could be used to estimate labor cost per line item as a ratio of the revenue.
Next iteration: customer-level adjustments
Different customers can legitimately cost more (or less) to serve due to negotiated terms, volume discounts, SLAs, or complexity. The next iteration introduces customer adjustments while preserving GL totals:
This ensures customer-level adjustments reallocate costs across invoices and customers but the sum still equals the GL. If you also need to hit explicit customer targets (e.g., contractually specified cost shares), apply raking / iterative proportional fitting to satisfy both the GL total and customer totals while maintaining proportionality.
Controls
Cap factors (e.g., 0.5–1.5) to avoid extreme swings.
Version and approve factors monthly; require a rationale (contract clause, SLA, brokered freight rule, etc.).
Surface a Customer Adjustment Impact report: baseline vs. adjusted margin deltas by customer/product.
Why this works
Again, this is an estimate and can be used for directional assessments, but is not as accurate as job level tracking. It is a good proxy when you do not have job level tracking and you are intending on putting job level tracking in place. It works because:
Business-informed mapping (weights and customer factors) that’s transparent and versioned.
GL-tied and reproducible with logged variances and true-ups.
Actionable detail at the invoice line level for customer, product, and location profitability—improving as more granular data becomes available.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
PE teams need numbers that are consistent across systems, comparable across companies, and traceable to transactions. Two situations come up repeatedly and benefit from the same architectural patterns.
Use case 1: One portco, many systems, one cohesive report
Situation. A mid-market company runs multiple ERPs and adjacent tools including billing, HR, CRM, and eCommerce. Month end close is slow, product/customer/job margin is unclear, and every board request becomes a bespoke spreadsheet that takes time from skilled people to produce and validate.
Design choices. Keep each source/location in its own site model (Bronze/Silver) and expose a normalized view in a governed Gold semantic layer. This avoids a brittle, one-time “merge” and lets each dataset evolve independently. GL accounts map to Income Statement/Balance Sheet through an auditable report-line mapping that’s reused in both transforms and rollups. Deterministic, namespaced surrogate keys prevent ID collisions across systems. Reconciliation is part of the product where invoice-level revenue and COGS tie to GL totals, with a variance registry capturing timing and reclass explanations.
What changes for the business. Finance works from IS/BS/Cash that drill to transactions and tie back to the ledger. Unit economics can be examined by product, customer, or job using driver-based allocations with sensitivity checks. Working capital and AR aging are reported consistently across the portco giving insight into cashflow analysis and working capital. Self-service BI through Power BI or Tableau sits on a semantic model that reflects the finance manual, with row-level security and visible “data as of” status.
Use case 2: Portfolio-wide visibility through normalized revenue & cost categories
Situation. The sponsor needs a consolidated view across companies with different ERPs and charts of accounts. Today, general ledger reporting categories such as revenue and cost is labeled specifically for that company’s needs and is inconsistent with the other portcos in the portfolio. This limits operators and partners from getting comparable views of company health that quickly diagnose successes or problems.
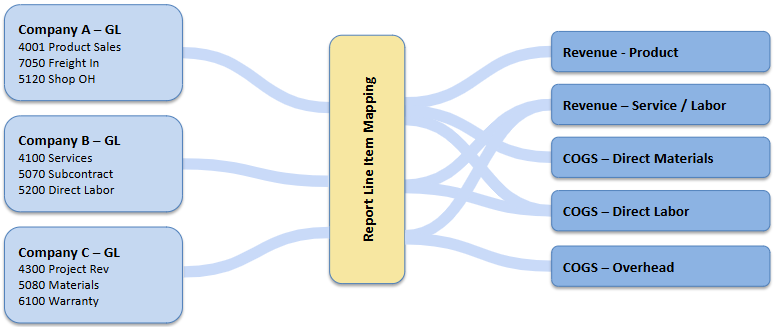
Design choices. Standardize the definitions, not the systems. We implement an effective-dated report-line mapping that assigns each company’s GL accounts to a common Income Statement structure. Two focal points:
Sales/Revenue categories. Normalize to a shared set (e.g., Product Revenue, Service/Labor Revenue, Project Revenue, Freight/Handling, Discounts & Rebates, Other Income). Where possible, introduce common Sales Categories as reporting line items in the GL to group operationally similar sales items.
Cost categories. Normalize COGS into consistent buckets (e.g., Direct Materials, Direct Labor, Subcontract/Outside Services, Freight In/Out, Manufacturing/Shop Overhead, Warranty/Returns) and OpEx into standard lines (e.g., Sales & Marketing, G&A, Operations, Technology). If unit economics are in scope, define allocation rules (e.g., shop overhead to jobs, cloud or distribution costs to products) but keep them versioned and reversible.
Each company retains its own facts/dims and refresh cycle (site models in Bronze/Silver). Portfolio views union those stars in Gold with a Company/Location slicer and a consistent fiscal calendar and FX policy (source, rate type, and timing). Exceptions (e.g., unique revenue treatments, local GAAP nuances) are handled via override mappings with rationale and dates, not ad-hoc edits.
What changes for the business. Sponsors and operators can compare consistent margin and expense structures across entities: revenue by normalized category, gross margin by product/service, COGS composition, and operating expense profiles—drillable to transactions and tied back to GL totals. Board packages, lender updates, and operational reviews draw from the same definitions. One delayed company doesn’t block the view; it’s shown with freshness status and can be temporarily excluded without breaking the portfolio roll-up.
Platform considerations (people and workload first)
Platform selection follows the operating model and who will support it after go-live. We do not dictate technology decisions, rather understand the situation and recommend the best platform for the situcation:
Microsoft-leaning organizations with minimal IT and Power BI usage. A Fabric-centric stack reduces moving parts: capacity-based compute, OneLake storage, data warehouses and a native semantic model.
SQL-heavy teams needing strong cost isolation and external sharing. Snowflake provides per-team virtual warehouses and straightforward data sharing.
Engineering-led teams with notebooks/ML and streaming needs. Databricks (Unity Catalog + Delta) fits open formats and Spark-centric workflows.
Any of these can implement the same pattern—Bronze (raw) → Silver (curated) → Gold (semantic)—with idempotent, replayable pipelines, effective-dated mappings, and visible run logs. The right choice is the one your support staff can confidently operate.
Summary
In both use cases, the value comes from consistent definitions, transaction-level traceability, and an operating model that scales across companies without forcing system uniformity. The patterns above provide a practical checklist when scoping similar work.
About K3 Group — Data Analytics
At K3 Group, we turn fragmented operational data into finance-grade analytics your leaders can run the business on every day. We build governed Finance Hubs and resilient pipelines (GL, billing, CRM, product usage, support, web) on platforms like Microsoft Fabric, Snowflake, and Databricks, with clear lineage, controls, and daily refresh. Our solutions include ARR Snowball & cohort retention, LTV/CAC & payback modeling, cost allocation when invoice detail is limited, portfolio and exit-readiness packs for PE, and board-ready reporting in Power BI/Tableau. We connect to the systems you already use (ERP/CPQ/billing/CRM) and operationalize a monthly cadence that ties metrics to owners and actions—so insights translate into durable, repeatable growth.
When we engage with retail prospects for our services, the first thing I usually ask is, “Are you setting prices in a spreadsheet?” If the answer is yes, likely you are experiencing challenges with your ERP or Host Merchandising system that were insurmountable and lead you to externalizing price setting through a spreadsheet. Often it is not just a single spreadsheet, but many spreadsheets that must work in unison to deliver prices.
Spreadsheets aren’t the only cause of pricing problems. In one case, we saw a retailer that has an optimization tool, but can’t reliably get prices down to stores. This is a price execution problem rather than price setting. Regardless of the reason, prices have to be set and sent to where customers can see them and problems can arise along the way that ultimately impact your profit.
If you suspect you might have pricing problems, how do you find out? We typically start analyzing where errors are the most obvious. At the highest level, commercial companies sell products for a price, customers buy the products, and you can check if the price for which you sold the product is the same as what you expected. The specific points where errors occur differs by industry but for retail, you can typically start with:
Store operations. Store operations will typically be notified by sales associates when prices are wrong. Track how many wrong prices are reported per week and which stores have errors.
Take a sample of orders and re-price them. A random sample will give you an indicator of if there are pricing errors.
You can then quantify the financial impact of the price errors. Products can be overpriced or underpriced and you can calculate the difference from the actual price. If it is overpriced you risk losing a sale. You can also undermine customer satisfaction but that is tougher to quantify. An underpriced product will impact profit and is easily calculated. Secondly, when you identify pricing errors it takes time and effort to correct the price. This has a cost in that an employee must analyze the error, correct it and move it through the systems to eCommerce or the POS. For example, you can review the analysis from the metals company we worked with years ago. Even though it has been 15 years, many companies still manually set prices in spreadsheets and experience similar error rates.
Once you realize how much price errors cost, you can figure out how to correct them by reviewing the process. The metals producer mentioned above found they had a 5% error rate on all invoices. This error rate is not uncommon when there are manual steps involved. They analyzed the process from start to finish. We used a similar approach and mapped it to fashion customers where we’ve seen a multi-step process that includes:
Merchant sets initial regular price
Merchant sets a calendar for promotions
Merchant defines promotions and a pricing administrative team executes them
Merchant sets mark down cadence for the season and pricing administrative team executes
Prices are sent to store
Store associate moves items and tags them
Where can this process go wrong? It’s best to do a thorough review of the process. What we’ve done in the past is to look at each step, interview the people doing the task and map out the steps and tools. For fashion, here are typical areas of opportunity:
Merchant sets initial regular price. When a product is introduced, the merchant sets the regular price. They typically define price points to target and then assign specific styles to each price point. A style is broken down into style-color-size combinations. This explosion of permutations is where the process gets cumbersome. For the most part, to make it easier, a style is generally priced the same but there are exceptions for size and color. Then, if you’re dealing with multiple currencies the process expands for each of the countries you’re dealing with. Price errors can occur when products aren’t mapped correctly or while converting prices for different countries.
Merchant sets calendar for promotions. The promotion calendar is built for the season but initially specific promotions are only defined at a high level. I’m calling out this step because merchants use it for planning but they’re not assigning the specific promotion yet.
Merchant sets promotion. When the promotional event is closer, the merchant will set the promotions. This can be specific discounts for a category, price points for a set of items, buy X get Y, or anything else a merchant can dream up. Usually, a merchant will define these in as much detail they can within a spreadsheet. Then, they hand it off to a pricing administrative team for execution. The interpretation between what the merchant wants and what the administrator enters can be a source of errors. For example, the merchant may inadvertently copy a style from a previous promotion or make an error while assigning a given item to a promotion. The pricing administrator may be able to catch the errors, but some errors will slip through.
Merchant sets mark down cadence. Depending on how a product is selling and how much inventory is left, merchants will set mark down cadence. These are hard marks geared towards optimally selling through the inventory by the end of the season. The use of separate systems for planning and executing these markdowns can lead to errors. Individual styles are marked down based on manual analysis or an optimization algorithm. If there is no systematic hand off between setting the prices and executing on them, problems can occur.
Prices are sent to the store. Once prices are set, they must be transmitted to the stores. Given that each store has their own point of sale system and might have different prices, promotions, or markdowns, most stores get their own set of prices and rules. For a large retailer, there can be 400 or more individual systems. Each system is a potential failure point given that the POS must receive the prices, load them, and pull in the rules.
Store personnel moves items and tags them. In parallel, promotional sheets are provided to the stores for product placement, promotional signage, and prices. Any number of issues can occur here. Tight coordination is required at each store to insure the prices are correct on the tags and the products are in the right spot for the given promotion.
Reviewing this process can reveal areas of opportunity to plug the holes. In this example, an up front system that allows the merchant to directly enter promotions or price changes directly would eliminate the opportunity for confusion with the price administrator. A system to quickly and reliably transmit the calculated prices to the POS might be needed. Alternatively, the POS could call out to a central pricing system which would eliminate the need to transmit the price data. The promotional and placement sheets that store personnel use could be generated out of the price execution system rather than being created manually. In some cases, electronic tags could be used. Regardless, once we’ve identified the most egregious spots we tackle them first, then move to the next ones. Typically, the solution relies on systems that can keep all the relationships in sync. It usually includes better processes as well. We look forward to learning about your specific processes and how we can help improve them.
Pricing errors leak profit
Pricing errors leak profits and they could be dramatically reduced with some effort. Companies that have straightforward list prices are much easier to manage then when companies negotiate complex contracts. Pricing errors are common place when companies negotiate regularly because there are so many exceptions to prices and conditions that sales people agree to which must first be put into a contract and second either executed by sales reps taking orders or automated into a system. This exception process leads to a lot of errors.
Our customers cut across many different industries and these issues are prolific whether you are in metals, high tech, insurance, or other business to business situations. One of our customers in the metals industry performed an extensive Six Sigma study prior to engaging us. The study found their sales process and inter-communication caused thousands of problems a year. The quantifiable errors cost them $1.4M a year and the upside was most likely $5M – $7M a year.
In Six Sigma, it is critical to have a well defined business case that outlines the purpose of the project as well as a goal statement that addresses the business case. For the customer, the business case was obvious:
$750 million in sales, 60 thousand invoices, 3 thousand discrepancies.
No system in place to verify accuracy of contract and pricing for orders.
Loss of revenue, customer confidence, control of pricing in marketplace.
And the resulting goal statement was defined as:
Improve competitive pricing and invoice system for quarterly savings of $350K.
The customer’s first priority was reducing pricing errors in accordance with the business case and goal statement. Today’s market requires more extensive information on invoices than in prior years including the price and how the final price is derived. Their price components were base price, alloy surcharges, scrap surcharges, freight, freight equalization, and fuel surcharges. Each one of these components were either contract values or tied to a monthly index average. The steps for calculating and looking up values produced significant errors as shown in Table 1.
Total Invoices
Price Errors
Input Errors
Retro Price
Late Price Sheet
Incorrect Price Sheet
Plant 1
561
225
5
21
93
217
Plant 2
39
31
2
0
0
6
Plant 3
489
220
2
31
103
133
Plant 4
411
248
8
4
45
106
Plant 5
221
29
27
4
6
155
Total
1721
753
44
60
247
617
% of Reasons
43.80%
2.60%
3.50%
14.40%
35.90%
% of Invoices
4.20%
1.80%
0.10%
0.10%
0.60%
1.50%
Avg cost/yr to correct
$348,503.00
$152,483.00
$8,910.00
$12,150.00
$50,018.00
$124,943.00
Table 1
This table looks at invoice discrepancies only when payments received did not match the invoiced amount. The number of invoice discrepancies were 4.2% of the total 60,000 invoices per year. Errors were broken down into five categories including:
Price Errors, which were mis-calculations or incorrect lookups of price components.
Input Errors, which occured when transposing prices from spreadsheet calculations to the invoicing system.
Retro Errors, which were caught after the fact and changed.
Late Price Sheet, which occured when sales people failed to get price changes in on time before invoices were set out.
Incorrect Price Sheets, which were spreadsheets maintained by sales people that had errors or were interpreted incorrectly.
We worked with them to eliminate all of these errors by using a centralized pricing structure and automatically generating price sheets. Sales people used the tool which had a similar interface as a spreadsheet which they were familiar with and prices were automatically stored in the central system. So, when invoicing needed prices, they were always up to date and interpretation disappeared.
It was interesting to note in the study that more often than not, customers notified them when they thought they were over-billed, but customer reported under-billing was almost non-existent as shown in Table 2.
January
February
Location
Over
Under
Over
Under
Plant 1
$39,867.13
$0.00
$6,965.65
-$232.35
Plant 2
$20,895.40
-$2,171.66
$5,842.22
$0.00
Plant 3
$29,933.82
$0.00
$3,282.29
$0.00
Plant 4
$13,555.53
$0.00
$8,392.71
$0.00
Plant 5
$1,700.74
$0.00
$87.73
$0.00
Monthly Total
$108,124.28
-$2,171.66
$24,803.08
-$232.35
Running Total
$108,124.28
-$2,171.66
$132,927.36
-$2,404.14
Annualized Rate
$1,297,491.36
-$26,059.92
$797,564.16
-$14,424.84
Table 2
Statistically, the over and under billing errors should have been similar. In the customer’s case, only one customer actually called back when he was under-billed.
As mentioned previously, with the new system the prices were correct the first time. When we piloted the system, they checked 5 customer’s prices for a month period and found over $77,000 in under-billing that would have previously gone unnoticed.
The Six Sigma study also took an in depth look at why errors occurred. The source of errors fell into the six bins shown in Illustration 2. The main source of errors was the loose price sheet document, which they called a CPF. This document was managed by sales people, but with little structure. Sales is a creative process so sales people needed flexibility in managing customers, but the loose form significantly contributed to errors.
Market Environment
CPF Document
Pricing System Errors
CPF Interpretation
Time of Order vs Time of Shipping
1. No time for detailed price agreement with customer
1. No requirement for documenting agreement with customer
1. Same person not always available to price
1. Long learning curve for interpreting CPFs
1. Lack of need for documented agreement with customer for specific delivered price
2. Customer’s system is not compatable with CPF
2. No time for detailed price agreement
2. Input error prone
2. Complexity of CPF, agreement, non-standard info sources
2. No comparison of pricing to customer PO
3. Information not received in a timely fashion
3. CPF constructed several days after agreement
3. Illegible, handwritten info
3. Inconsistent interpretation of CPF and add-ons
3. Price is optional part of order entry
4. Amendments not received
4. Pricing using wrong sheet
4. Calculation errors
4. Same person not always available
4. Price at order entry not transferred to pricing
5. CPF not updated
5. Information not received in a timely fashion
5. Transposition errors
5. Didn’t capture info correctly from CPF
5. No checks on previous billing history
6. Information not available on time
6. Amendments not received
6. Employees time constrained
6. Missed charging for extras
7. No verification process with customer
7. CPF not updated
7. Documents hard to read
7. Misread the CPF
8. Format of CPF not compatible with pricing needs
8. Information not available on time
8. Working from the wrong sheet, line, or column
9. Information not available on time
9. No controls to ensure correct info is being used
9. No controls on using wrong infor from CPF
10. Price protected orders/shipments hard to ID
11. No controls on what ammendments are used for pricing
12. No controls on effective dates
We were able to address the majority of the error sources discussed above without interfering with the creativity of the sales people. By centralizing pricing, standardizing calculation methods, and tables, we brought structure to the process but allowed sales people to customize price sheets according to individual needs.
Metals pricing is particularly complicated and if you’re going to tackle your own pricing errors, you don’t necessarily need to do a Six Sigma study before you start. It certainly helps to unearth the estimated savings, but you probably already have a gut feel for where the leaks are coming from. The first thing to do is get a handle on all the contracts floating around and the special conditions. You can segment these, put them in spreadsheets and start from there. Once you have the the special conditions isolated, you can put together a framework for exceptions that captures the majority of the conditions. Then, you can offer those exceptions as the only exceptions you’ll allow from sales reps. Giving reps some freedom within a process gives them some negotiating latitude that you can put into a system to cut down on errors. It’s not simple, but it can be done and will help increase profit.
Pricing errors take time to fix
One of our customers, a global clothing and accessory retailer, was looking for a more effective way to manage their prices. Competitive threats precipitated the need to change prices frequently which stressed their existing process. Their merchandising and pricing teams struggled with correcting price mistakes quickly and identifying where errors occurred. Their process was caught in a cumbersome coordination between their host merchandising, spreadsheets, eCommerce, and Point of Sale systems. The system we implemented made the process more effective, improved the speed at which they could respond to price mistakes, and gave them visibility to where the errors were happening. Below is a review the benefits they received and how we helped them.
Business Case. It is critical to have a well-defined business case that outlines the purpose of the project as well as a goal statement that addresses the business case. In this case, the objectives were clear:
Ability to react quickly and flexibly to local market conditions
Correct mistakes faster through direct integration into downstream systems
Identify problems faster with better visibility into where the errors occurred
Consolidate pricing activities into a single system of record
Better flexibility in local markets. As the competitive landscape changed, our customer needed the ability to change prices easily across local markets. While price changes were possible in their previous process, a lot of manual effort was required. Through the new tool and process we implemented, merchandisers were given the flexibility to change hard marks, sale, clearance, and promotional prices for any product and store combination. This laid the foundation to rapidly change prices. All prices are managed centrally and then individual files are generated for each store or the eCommerce site. In the future, they may take advantage of real time APIs which would allow systems to immediately receive price updates without any delay.
Correct mistakes faster. Correcting mistakes faster was a top priority in accordance with their business case. Today’s retailers must have accurate pricing and be able to react quickly to errors. The previous process would take about 2 to 2.5 hours to update mistakes or simply send out midday updates. With the new solution the time was slashed to 20 minutes. The previous process went through several steps with intermediary systems. Now, they are able to generate the price change directly for the given stores and distribute the files immediately which are then transferred to the POS.
Gaining visibility to pricing outcomes. Prices were buried in spreadsheets and often it was difficult to determine the actual effective price given overlapping hard marks, promotions, and stackable coupons. In many organizations different people are responsible for merchandising and marketing and the ultimate margin is estimated until sales data is returned. With the new tool, users are able to see how the prices were built, who created the promotion or coupon, and when it is effective. The price administrators are able to search across the time horizon to see if a future price change will affect their expected margins. Prior to the new process when a store recognized a price was wrong, they would notify the business who would then go through a flurry of emails to figure out where the error occurred. Now, the pricing team is able to look up the item, find out exactly which promotions are applied, and correct the error quickly.
Consolidating pricing activities. In the previous pricing process, activities were split between the host merchandising system, spreadsheets, and a separate system for multi-item deals. Our customer wanted to consolidate those functions to have a single system for hard marks, clearance, sale, promotions, and deals. They were able to do that through the new system which allows them to manage their prices and then distribute to their various channels.
Future considerations. Looking into the future, our customer will be able to move price entry into the hands of the merchants rather than having a dedicated team for price entry. This will allow the pricing team to focus on more strategic initiatives. The next area of focus is store communications. They manually create a document for store managers that tells them price changes and product placement. With the addition of product placement information, the new solution will automatically generate this document. This will streamline the process the merchandisers do to get information to the stores. Finally, they are considering an Asia Pacific rollout and real time connections to systems to cut the response time further.
We were able to address the issues discussed above working with a cross functional team of merchants, eCommerce, IT staff, and pricing managers. Working with these teams, we identified the critical issues with the process and implemented new capabilities that ultimately saved them time and money.
Preparing for an optimization opportunity
Pricing optimization is one of the best tools you have at your disposal to increase your profit. Studies have shown base price optimization can yield an increase of 2% – 5% in margin, promotional optimization can yield 5% – 20% and mark down can lead to a 6% – 10% improvement. That is too great of an opportunity to ignore. If you are not using science and have a good amount of transaction data, then you could almost certainly benefit from using optimization. If you are considering optimization, you can take steps to make sure you are fully prepared to take advantage of the solutions.
First, a brief explanation. Products go through different lifecycles which closely tracks with what types of algorithms you can use to optimize prices. Many products adhere to a lifecycle where the product is introduced, then sales increase, eventually even out, and finally decreases at the end of life as inventory is sold through. Each stage in the product lifecycle requires different optimization techniques. The initial and day-to-day price is established at introduction and you monitor performance for a period of time before using promotions to increase sales and profit. The initial price can be optimized but is typically bounded by constraints and business rules you have which limits optimization. Promotions allow more freedom in using elasticity to understand what the best price is and mark down optimizes your sell through.
The general barometer mentioned above is valid in most cases and you can do some high level analysis to determine what benefits you can achieve, but truthfully if there is an opportunity you won’t be able to realize the benefit unless you can actually do the optimization. So, instead of discussing a process for estimating the opportunity, we’ll discuss how you can figure out if you can unlock the opportunity.
For optimization to work, you must have enough data and price variation. The data elements needed depends on the type of optimization you are doing but you always need base data like products, location, and sales history. You might also need things like inventory positions, marketing instruments, cost, and promotions. Below we explain what each element is and how it relates to the specific optimization:
Sale price. It is important to have the price the customer sees when they make a purchase. As simple as this sounds, its sometimes difficult for companies to get this price. For example, if you’re a manufacturer, distributor or any other entity that does not have control over the final price the customer sees, it may be difficult to get it. Retailers have the transaction data, but in many cases the data isn’t clean and needs to be fixed.
Number of units sold. The transaction data will also include the number of units sold per location. Number of units sold and the sale price are the foundation of your historical data which is used in the forecast. If you can’t get the number of units sold, you can possibly get the number of units shipped to a given location. This isn’t ideal, but it’s better than nothing.
Price variation. Sometimes it is difficult to get enough data to build an accurate demand curve. But you can get it good enough then use basic analysis to set your price. Price variation can come from many different sources such as discounts, coupons, and price errors. It is essential to know the regular price, the promotional price, and the date range when the price was in effect.
Cost. When optimizing for profit, you’ll need to know how much you paid for it.
Marketing instruments. The marketing instrument used can influence the effectiveness of the promotion significantly. When capturing the price variation, it is important to know exactly what instrument was used because not all instruments are created equal.
Competitive prices. If you are in competitive markets, you’ll need the prices these competitors and the proximity to your stores. The same is true for your eCommerce channel. This data is tied to business rules which drive day to day pricing.
Inventory. If you’re trying to do mark down optimization, you’ll need inventory positions at each location including stores or distribution centers. Inventory would also include any future buys that have been made already.
Not all of this data is necessary to get started with optimization and you can add new data streams after your initial dip into the optimization pool. The basis for optimization is the forecast. If you don’t have enough price variation or data, you may need to substitute similar products, aggregate at a higher level, or use other forecasting techniques to get an accurate picture of demand. When you are trying to evaluate whether or not you can do optimization, the data is analyzed to see if there is enough to feel statistically confident.
When you’ve verified you can do optimization, what is all this data used for? For day-to-day pricing, a lot of the prices are dictated by business rules. These typically restrict the prices in a narrow band based on competitive products, target price points, and other factors. After that there is a small amount of room to maneuver using price elasticity. Promotions have more latitude in using price elasticity and also consider cannibalization and halo effect from other products. Finally, mark downs are constrained by available inventory and try to maximize your sell throughs based on your business goals.
If you pass the litmus test for having the data, you have an opportunity. The next step is to go through the process of collecting, cleansing, and preparing the data for an optimization tool so that you can unlock the potential benefits. In a future article, we will discuss how you use this data in each of the different types of optimization.
Take a look at these other links for more topics on pricing
If you’ve done your homework and are confident you have a pricing opportunity, it’s time to start thinking about a project. Depending on what you’re doing, the project could be extensive or it could be a quick hit. We’ll cover scoping the project in the next articles, but first some things to avoid. Pricing projects, like any enterprise project, are subject to similar pitfalls that can be avoided or mitigated to ensure a successful project. In our experience, here are some of them:
No executive sponsorship. Pricing projects are resource intensive and touch a lot of parts in an organization. Without executive sponsorship, these projects rarely have a chance. Clear leadership helps align key resources that need to contribute on the project and ensures you have their attention.
Competing priorities. In one company, the leadership had made a decision to go with one software solution but the project team didn’t support the decision. The project team worked with the product and halfheartedly attempted to get it working but ultimately opted to abandon the solution for their preference of a custom-built solution in contrast to the leadership’s direction.
Too many cooks in the kitchen. Without executive sponsorship and a clear direction, different factions in the organization align towards competing objectives. Then, they’re compelled to ‘right the ship’ in accordance to their own objectives.
Underestimating the scope. In another case, the level of effort for a pricing project was way under estimated because the scope had not been defined. The inexperienced leadership made knee jerk decisions on timelines in contrast to the advice of the more experienced team members. Pricing projects need well defined requirements and typically require a lot of integration which takes time.
Data availability. Pricing projects require data. Ultimately a pricing solution is a calculator – it brings data in, calculates and computes, then sends data downstream. If you’re not prepared to get the data out of your systems, don’t start the pricing project. As part of a readiness exercise, you might want to consider a master data management project or something similar to ensure data is available.
Limited business experience from implementers or no technical expertise in business owners. Someone on the team needs to bridge the gap between the business side and technical side. These are two different languages and unless someone translates, you won’t end up with what you want. There are often tradeoffs in implementations and if the technical folks don’t understand the business benefits or the business folks don’t understand the difficulty of implementing features then you can end up with an end result that misses the mark or cost overruns.
Ill-defined benefits. This is the big one. When benefits are clearly defined, everything else follows. Leaders support strong business benefits and competing priorities fade away.
These projects are typically transformational and affect a large part of your sales organization. Because of that, they really need strategic sponsors at the executive level in a company. They aren’t easy and the process changes that permeate after implementing these solutions are as complicated as the technical challenges. Ignoring this reality just puts the project at risk.
All parties from the top down need to be in alignment. If any link in the chain isn’t on board, it will again jeopardize the project. This does not mean suppress critical thinking or challenges to the majority opinion, but there needs to be a set of strategic goals that everyone agrees with so everyone is marching in the same direction. Here are some steps to take to mitigate the above risks prior to starting the project:
Clearly define the business benefits. This is one of most important things to do when starting a project. The business benefits guide the project and ensure when you have disagreement you can balance the discussion against the benefits you are trying to deliver. In addition, as the project progresses you should measure the business benefits achieved and evangelize the results with business owners and executives. On the flip side, if it is not achieving the expected business benefits, realign towards them, revaluate, or cut your losses.
Align the business leadership. Once the business benefits are defined, it is easier to get an executive sponsor. The executive sponsor should support the business case whole heartedly. If the executive sponsor has a lukewarm feeling towards the business case, he or she is less likely to be the evangelist you will need with the other company leaders.
Always listen to the end users. Success lives and dies with the users. If they don’t accept the solution or it is too difficult to use, they won’t adopt it. In our projects we rapidly prototype and regularly demonstrate the results to the end users to solicit feedback. You run the risk of getting additional scope, but this can be managed by putting it in the queue and aligning to the business priorities.
Keeping these risks and mitigation points in mind when embarking on a project is important. In the next articles, we will walk through project planning and scoping.
Planning a Pricing Project
Structurally, pricing projects aren’t much different than most enterprise software projects. Planning is the key to success. The first step is to work with the client team to develop an implementation strategy that works for all parties. The plan would have a firm scope for the first phase and potential scope for subsequent phases. This allows you to be agile as new information and situations come to light.
An implementation strategy will help guide the project and should address the following:
Document the expected drivers of benefit and the changes that enable and sustain those benefits
Define the business functions each application will cover during each phase
Define the data flows and integration methods between the applications for each phase
Assess the risks and plan mitigations to keep the project on track
In addition, implementation success factors should be discussed. Some of the factors that might be included are:
Involve key business users throughout the project. Users aid in defining requirements, setting scope, reviewing prototypes, performing acceptance testing, training other team members.
Keep implementation phases small. Phases should focus on a “minimally viable product” approach to manage risk and maximize the opportunity to learn and adjust as you go.
Maintain a consistent team from start to finish. This allows you to maintain institutional knowledge, minimize handoffs, more effectively support live issues and modify earlier work when needed.
Next, what are the pricing pain points you are trying to fix? When we identify the pain points, we will also estimate the financial benefit or productivity gain expected from addressing the issue. If you went through the process of identifying your pricing errors and analyzed the causes, you will have a good idea of what your pain points are. Here are some typical pricing pain points that we have seen in implementations:
Prices aren’t making it to stores quickly and reliably
Customers are demanding instant access to their loyalty points and stored coupons
Network connections are unreliable to the stores and often go down
There are potential price conflicts or margin leaks between price changes, promotions, markdowns, and coupons
Prices are managed in complex spreadsheets and there is an associated risk of making pricing errors often with the processes
The need to keep prices and promotions across channels aligned
These are some example of pain points that might exist in an organization. As mentioned, this list can be distilled from the analysis exercise of determining where your pricing errors are coming from. The list might also contain tangential pain points that aren’t directly causing pricing errors, but do cause frustration with the team that manages prices.
Rather than a big bang approach we subscribe to many different business releases that focus on key functionality. But where do you start? For our projects, we initially use a broad brush to identify how complex the different features are and balance that against the pain points. A business release would have well defined benefits that are attributed to specific feature requests. There are typically many different business areas you could start with for example a specific set of features, brand, geography, set of stores, or channel. We typically look at the following criteria in deciding where to start:
Start with a quick win. Often one of the best places to start is something that would address one or more key pain points and keep the timeline short. If you sized the complexity of the features and cataloged the pain points, you should be able to gauge what would be a quick win.
Understand the quality of the current data sources. Poor data quality is an issue with most projects and can bog down any timeline. A quick assessment of where and how to get the data, what kind of holes exist, and what kind of transformation should feed into your assessment of complexity.
Supportive business group. Another factor is what business groups are supportive of change and have the bandwidth to help drive the early implementations. If key personnel aren’t available such as business owners, users, or IT staff then your timeline could be in jeopardy.
Participation. Determine what level of participation the business can provide during the project.
Competing projects. Determine if there are other active projects that would impact the same resources or systems.
Other priorities. Are there any business priorities that would need to take into account? In retail, we often deal with back to school or black Friday and have to plan around those events to ensure we aren’t impacting those critical times.
All of these factors should be taken into consideration when determining where to start. Once you nail down the initial business release, you can plan it in detail to determine the expected timeline and cost. At the same time, you should identify the future business releases you expect to follow. You don’t have to plan the future releases in depth but should have a rough idea of complexity and cost which will drive your overall resource allocation and budget.
Pricing project structure
We find that taking bit sized chunks is best when deploying pricing projects. As discussed previously, we have a program planning phase where we determine what functionality would go in each business release. When we know what is in the first business release, we start the project. We typically use the following framework for a business release:
Requirements and blueprinting. Good requirements are essential to the success of the project. The first step is to comprehensively document the business user requests. This is followed by detailed user workflows, high-level data flows, and user acceptance tests. After this is documented, the technical architect and/or developers are consulted to get estimated timelines and balance technical feasibility against business goals.
Iterative config and development. Configuration and development are when the business features get codified. With enterprise software applications there is typically configuration work that tweaks the application to enable the features the business owners would like to see. There might be data modeling or price modeling that conforms to the needs of the input and output data. In addition, development work might be needed to fully realize the business owners vision. In either event, iterative discussions will take place between the architect and the technical implementation team.
Integration testing. After configurations or code is released, integration testing is done to finalize the data inputs and outputs and the interfaces that are used. The bulk of the independent work is done in the previous step and then end to end testing is done here. This could be flat files, real-time calls, or a bus. The data could be coming from multiple sources and be sent to multiple destinations. The complexity of this step could extend the timeline.
User acceptance testing. After the integration testing, user acceptance testing is done on the final functionality. In the config and development step we typically show the business users what will be coming, so they have a preview, then in user acceptance testing they work through the defined test cases.
Deployment and post move to production support. The last step is to deploy the functionality to production. The setup and installation is done prior to this step and here we would move data, code, and configuration to the production systems.
These steps are put into a more detailed plan with a business release taking a few months or longer. A typical schedule for a pricing project might be as follows:
In conjunction with the plan we develop a resource plan with the mix of team members necessary to deploy the project. In our projects we use consultants who are experts in the products we implement mixed with part time and full-time resources from the customer. We typically see the following roles are needed in varying degrees. On smaller projects, people can wear multiple hats to keep costs down, but larger projects typically require more dedicated roles:
Role
Responsibilities
Project Manager
Managing the project and playing an SA role, coordinating with AAP
Solution Architect
Solution architect would define and oversee the overall requirements, network architecture, solution approach, and integration architecture
Senior Integration Developer
Integration architect would define and develop the necessary integration functionality
Modelling Architect
Manage, define, and document the pricing model
Test Manager
Continuous testing and documentation would be performed throughout the project
Business Analyst
Analyzing requirements, working with modeling architect and integration development to deploy the solution
Developer
Additional development to support integration
In addition, the customer typically provides following roles:
Role
Responsibilities
Project Manager
Dedicated to the project
Subject Matter Expert
Significant involvement during program planning, blue printing, and testing phases. Need coverage of all the pricing processes
Legacy Data Owners
Need resources that understand the format and context of the data from the legacy systems that will drive the pricing process
Integration
Need resources to provide sample feeds from legacy systems, participate in the design of interfaces, support integration testing, and operationalize the new feeds
IT Operations
Participate in the design of the operational processes as the new systems come on line. Batch windows for feeds, SLA’s, backup / restore processes, initial loads, net change feeds, etc
Users
Participate heavily in UAT and as needed during blueprint and config / test phase
Steering Committee
Provide guidance during program planning and a monthly cadence to review progress and resolve management level issues
The plan is an union of required business functionality, success factors, resources, budget, and timelines. Once this is done, it is time to start implementing.
Take a look at these other links for more topics on pricing
In our consulting practice, we speak to many different retailers about their pricing needs. Recently, the requests we have fielded are trending towards what I would term a centralized pricing service. For many years across all industries the trend has been towards specialized services and we seem to have hit that point with pricing in retail.
In retail, we often see three systems that work in conjunction to deliver prices to customers: ERP (Host Merchandising), POS and eCommerce. Prices come from downstream and are aggregated or augmented in the ERP system and are sent out to POS and eCommerce separately. What retailers have found is that the ERP isn’t a very effective tool for managing prices, so they end up externalizing the pricing process in spreadsheets or custom systems.
This is because pricing sits in the void between eCommerce, POS, and ERP / Host Merchandising. Many off the shelf and homegrown eCommerce solutions struggle to handle the volume of data associated with the permutations between channel and location. POS is typically segmented for a single store and ERPs struggle to handle the transaction speed necessary for supporting real time or mass calculations in a timely manner. This leaves enterprise retail pricing out in the cold with a hodgepodge of spreadsheets and custom solutions.
What is driving the need for a centralized pricing service?
Consistent pricing. Customers are demanding that retailers give them consistent prices on the internet and the store.
Amazon. Grocery and fashion retailers watched as Amazon decimated other retailers and realize they have to make a change.
Hyper personalized offers. What used to work as location based offers don’t make sense with multiple channels, so retailers are starting to tie offers to specific customers to inspire loyalty.
Consistent pricing. In many retailers, the eCommerce and POS are typically two disparate systems often with different functionality. Maintaining consistency becomes an exercise in custom code or manual processes that break down. Customers don’t really care what your internal issues are, they just want to be able to go online, see a price, then go into a store and get the same price. And if they have a special deal because they’re a loyal customer, they want to get that same price in the store that they would receive online. It’s not a new or unusual request and it’s been an issue in retail for years. Customers are now getting frustrated and expect it.
Amazon. Amazon has been dabbling in grocery and fashion for years now. Then, they bought Whole Foods and are smack dab in the middle of grocery. At the 2018 SXSW I was in a session where the CTO of Amazon Fashion stood up and questioned a leading fashion retailer. They’re watching, learning, and getting better. It’s inevitable that they will figure it out and retailers need to be prepared. Of course, it’s not just Amazon, grocery and fashion have always had competitive threats. It’s just more pronounced with Amazon encroaching. Competitive and consistent pricing is one way to combat this threat.
Hyper personalized offers. As competition closes in, another tool to entice customers to continue shopping with you is personalized offers. In the past, retailers could offer location based or general coupons for customers. Entrepreneurial affiliates on the internet have rendered general coupons a shared secret that serve to simply lower margins rather than inspire loyalty. Retailers have since turned to coupons or offers that are tied to a particular customer. On top of that, hyper personalized offers push existing systems to their breaking point.
These are just three of the most prominent complexities that are difficult to address with current solutions. So, what would you need from centralized pricing service?
Fast. If you’re generating files for POS then it has to calculate potentially millions of price changes quickly and if you’re servicing internet requests, it needs to have fast response time.
Real time and batch interfaces. To serve different channel needs, the system needs to allow real time or batch interfaces. In some cases, some retailers are seriously considering real time interfaces from the POS which would negate the need for batch.
Pricing system of record. A centralized pricing service needs to be the pricing system of record including day to day pricing, mark downs, promotions, coupons, contracts, and all the history.
Fast. Whether you are enabling real time connections to your POS or generating files that will be distributed to your POS, a centralized pricing solution needs to be fast. Retailers that have hundreds of stores with localized prices can easily scale to millions of calculations. The system needs to be fast so you’re not waiting hours to get your prices out. Without a pricing service, ERP typically shoulders that burden and given the number of calculations needed would take hours to process rendering the ERP unusable during that time.
Real time interfaces. A centralized pricing service would be used for POS, eCommerce, and funneling prices back into your ERP or Host Merchandising system for financial calculations. If your infrastructure can handle it, real time interfaces are the best way to go because then you have the right price from your pricing system of record.
Pricing system of record. If you have a centralized pricing service, it needs to handle all pricing requirements. This includes day to day pricing in grocery, regular price in fashion, hard marks, promotions and coupons. Each of these are different events that change the price. They need to be tracked and historical records kept so that you can reconstruct the price at any point in time. In addition, some retailers have b2b contracts with customers, so the system needs to handle customer pricing for individual products or groups of products.
In conclusion, if you’re finding pricing is spread across several different systems, you’re having to piece it together and you aren’t sure if your POS prices match your eCommerce prices it might be time to consider a centralized pricing service. Leading retailers are trending in this direction and the flexibility a pricing service offers is tantamount to their success.
Pricing service deployment approach
Retail customers have different requirements on how their pricing execution service should behave. Some need it to feed their POS and eCommerce systems whereas others require real-time connections to improve functionality in limited POS systems. The approaches we use are centralized and distributed which translates to real-time execution or batch processing respectively. The decision on which to use depends on many factors including the customer’s intended use of the service, the levels of maturity of the IT infrastructure, and availability of staff. Both approaches have merits and customers must weigh the trade-offs before committing to an approach.
What is the difference between the two? Distributed is when you pre-process most of the prices, store them in a repository such as files or a database table, and then send them to the remote system. This allows central calculation of most of the prices with minimal additional calculations at the local level. Real-time is a service where the function of calculations is offloaded to the external system and accessed through callouts. The advantages and disadvantages of each approach are enumerated below.
Advantages
Disadvantages
Distributed
· Utilize existing price distribution infrastructure· Known file interfaces· Utilize existing operational procedures· Price authoring infrastructure simpler
· Less flexibility in promotions· No centralized validation for coupons or loyalty discounts· Potentially longer deployment time for prices
Centralized
· Easier consistency across channels· Quicker deployment time for prices· Real-time validation of coupons and other promotions
· More complicated infrastructure· More difficult integration
Often, it might not be a one approach fits all and you can employ both approaches. For example, in hardlines a distributed file would need to be sent to the price tagging system and real-time could be used online for pick up at the curb whereas the POS would also require a price file. What are the reasons to use one approach versus the other? We help customers make the decision by asking pointed questions such as:
How complicated are your promotions?
Do you want promotions that are more complicated than your POS can handle?
How much latency does your network have?
Can your POS handle real-time callouts?
How reliable is your network?
For example, you might use a decision tree like this:
This is just one example of how you arrive at the decision. Other factors might be budget, availability of staff, and any number of competing projects that would have an impact on a pricing service implementation.
We have seen an important motivation for using batch processing is that many retailers don’t trust their network. They feel they would like to use real time but their network isn’t reliable enough across all stores, so they need a local presence that can calculate the prices.
Here are some other reasons that would tip the scales one direction or the other:
Complicated promotions: Complexity of promotions is a factor that could lead a company down the real-time path. For example, if promotions are simple, then it might make sense to pre-process them and send them to the stores in batch. If they are complicated, you might be better off calling real-time because the work involved updating the POS system would be better spent integrating to a centralized pricing system.
Network reliability: Many retailers are reluctant to use real time connections because they trust their network 99% of the time, but not 100% and the slim chance that the network might go down precludes them from deciding on real time connections. There are hybrid approaches where most of the pricing information is sent to the POS and in case of a network disruption the POS can fail over to the local price files. However, as more and more critical services require reliable connections, the decision to migrate to real-time becomes easier for retailers.
Validated coupons: Another point of consideration is any promotion that requires validation. For example, single use or customer tied coupons need a centralized system to ensure the coupon hasn’t been used before in another store or a different channel. This can be coupled with a distributed approach for standard promotions and prices so that a real-time callout is only necessary when validating.
Utilizing existing infrastructure: When determining an approach, sometimes it is easier to get started by using the existing infrastructure and replacing the back end price authoring environment. This might lead customers to choose batch processing where they would be able to duplicate the existing files and limit changes to the distribution framework. By doing this, they would limit the impact on IT given the required code changes, testing, and system upgrades.
In both cases when implementing a pricing service, customers gain centralized control of pricing which leads to reduced errors, better traceability, and quicker execution. Ultimately, a customer will evaluate the objectives of their pricing service which will dictate the approach. Once that decision is made then we focus on the final network topology which we will discuss in the next article.
Take a look at these other links for more topics on pricing